Les avancées en intelligence artificielle (IA) ont un impact significatif sur l’automatisation de l’analyse des images aériennes et satellites. Cette analyse est cruciale pour la mise à jour des bases de données cartographiques, et permet de dessiner précisément les contours des objets à cartographier. Réalisée manuellement par un opérateur, cette tâche peut rapidement devenir chronophage et coûteuse.
Les Vision Transformers offrent de nouvelles perspectives pour le traitement des images. Là où les approches plus traditionnelles, telles que les réseaux convolutifs, peuvent être limitées dans leur compréhension globale de l’image, les Vision Transformers permettent de faire des liens entre des parties éloignées d’une même image.
Les capacités de l’IA sur l’image
Les tâches que l’IA peut résoudre sont variées et dépendent de la problématique à traiter. Voici quelques exemples :
- La classification : attribution d’une classe à l’image entière (par exemple, il est possible d’identifier le type de terrain dans le cadre de la classification de l’occupation sol) ;
- La détection d’objet : dessin de l’emprise d’un objet dans l’image (comptage des véhicules) ;
- La segmentation sémantique : chaque pixel de l’image se voit attribuer une « classe », avec une délimitation des différentes régions d’une image (e.g. zones agricoles/urbaines) ;
- La segmentation d’instance : chaque pixel de l’image se voit attribuer un « numéro unique » par objet de la même classe (identification individuelle des bâtiments).
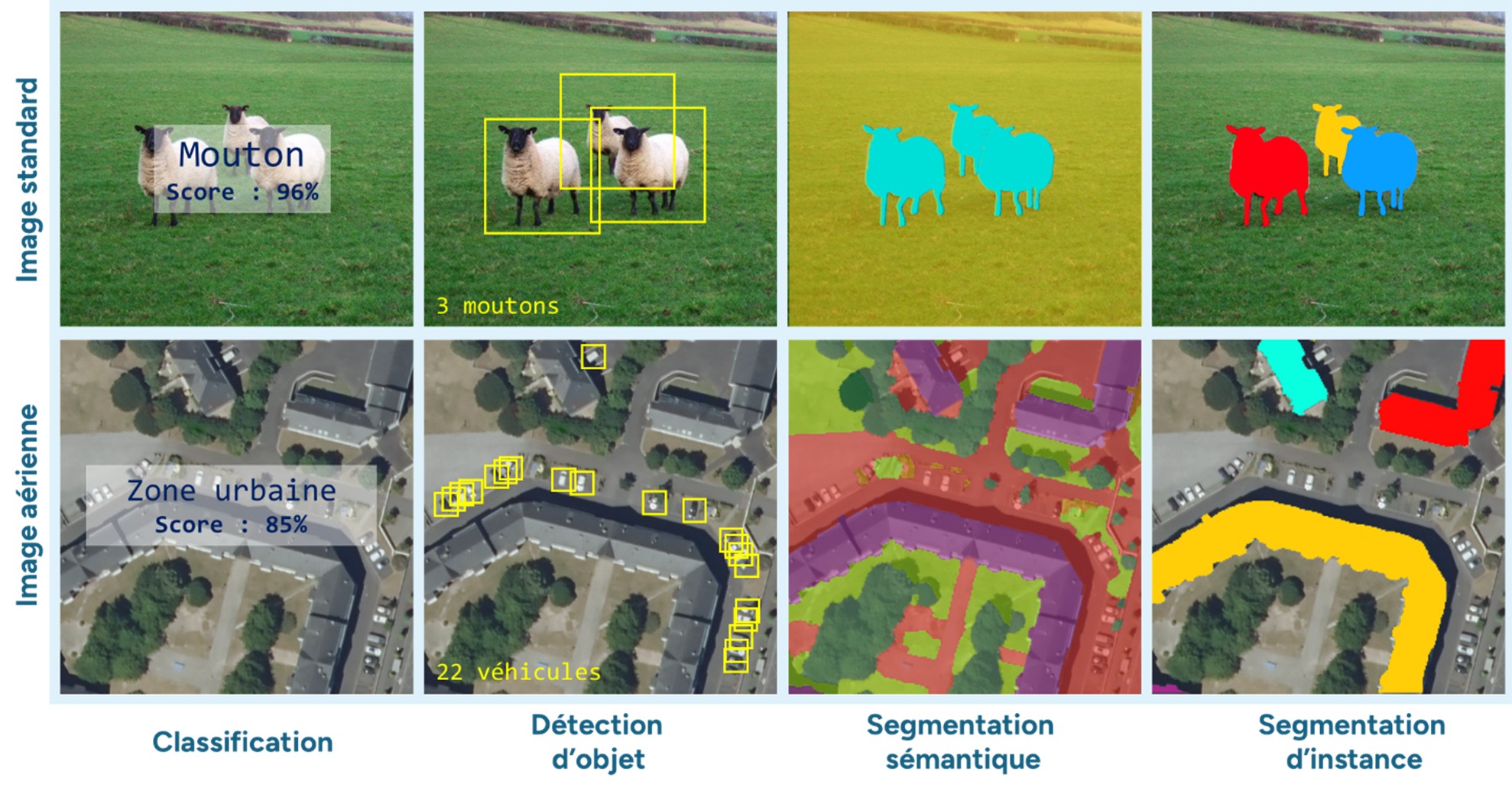
Différentes tâches d’analyse d’images par méthodes de deep learning
Elles sont aujourd’hui traitées par des méthodes de Deep Learning. Ces méthodes analysent les images afin de déceler les signatures caractéristiques des objets, et utilisent des architectures conçues comme des réseaux de neurones.
Traitement d’image par Deep Learning
Depuis une quinzaine d’années, les Réseaux de Neurones Convolutifs – de l’anglais Convolutional Neural Network, « CNN » – sont devenus incontournables en raison de leur efficacité pour extraire les caractéristiques spatiales d’une image [1]. Ils utilisent le principe des convolutions.
Une image est souvent représentée comme une matrice de pixels. La convolution applique des filtres à cette matrice pour extraire des caractéristiques spécifiques, telles que les bords ou les textures.
Un filtre (souvent une matrice de 3×3 ou 5×5), est glissé sur l’image. À chaque glissement, les valeurs de l’image sont multipliées par celles du filtre pour produire une nouvelle image. Cette répétition, à plusieurs échelles, permet d’obtenir diverses représentations de l’image.
Opération de convolution
Très performants dans la majorité des cas, les CNN présentent quelques limites. Ils permettent une extraction de caractéristiques locales, mais échouent à établir des relations globales dans une image. La « portée » de ces caractéristiques est déterminée par la taille du filtre de convolution, mais l’opération de convolution ne permet pas de créer des liens entre ces caractéristiques. Les Vision Transformers résolvent ce problème.
Les Transformers
Les Vision Transformers (ViT) [2] sont une adaptation des Transformers introduits en 2017 [3], et initialement conçus pour le traitement automatique du langage naturel. De fait, ils permettent d’établir facilement les relations entre les mots par l’analyse de leur contexte. Les grands modèles de langages, tels que ChatGPT, utilisent ce type d’architecture.
Pour illustrer, prenons une tâche de traduction, dont la phrase entrée par l’utilisateur est : “L’enfant joue dans le parc et il est très heureux. » Le mot “il” est une référence à l’enfant ou au parc ? Cette question, triviale pour un humain, est bien plus complexe pour une machine.
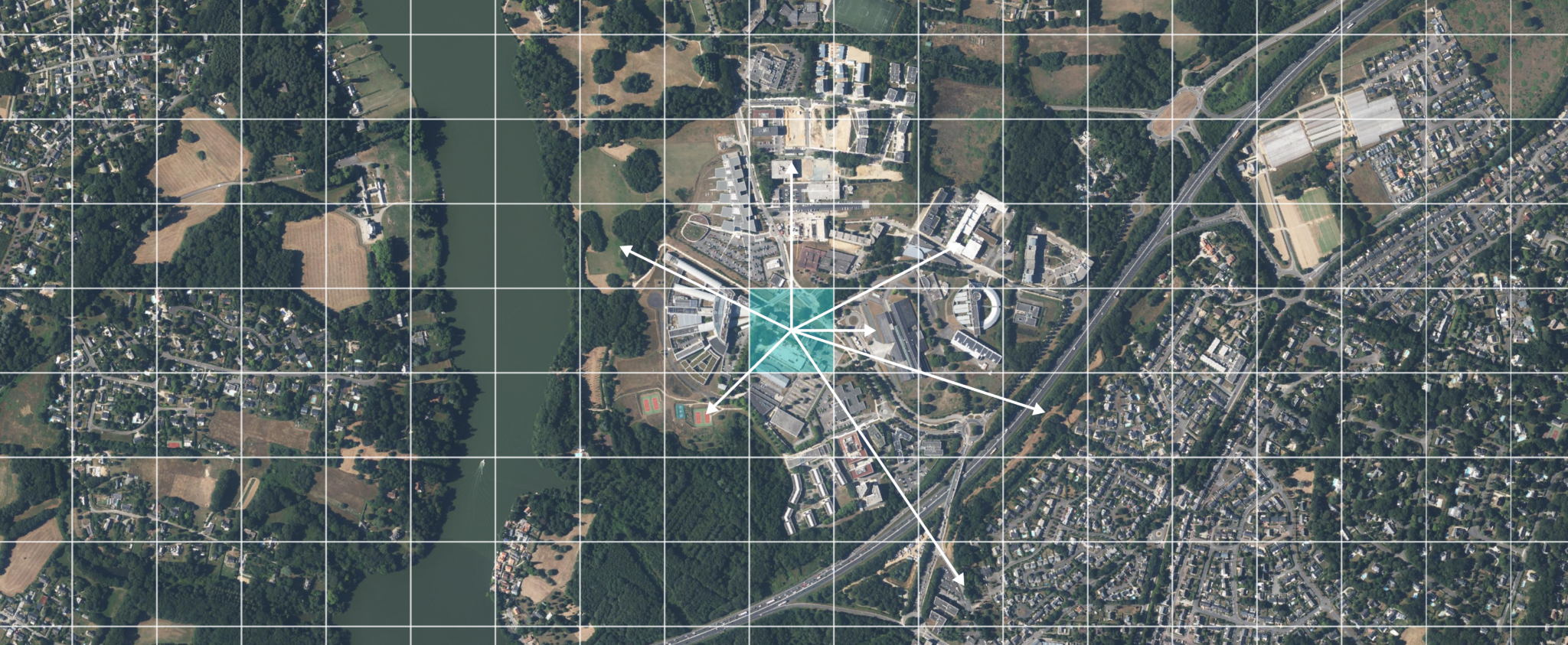
Illustration simplifiée du concept d’attention pour un seul mot dans une phrase
Les Transformers vont donc calculer, pour chaque mot, sa relation aux autres mots par un mécanisme appelé l’attention. De cette manière, le modèle identifie les mots sur lesquels il doit “prêter attention”, pour traduire chaque mot d’une langue à l’autre.
Les Vision Transformers
Les Vision Transformers (ViT) fonctionnent de la même manière que les Transformers. La principale différence réside dans la nature de la donnée. Au lieu de considérer une phrase en entrée, les ViT vont traiter une image.
Le ViT va commencer par découper l’image en différentes régions composées de plusieurs pixels (16×16 pixels, par exemple). Puis, de la même manière que pour les mots dans une phrase, il va établir des liens entre ces régions grâce à l’attention.
Illustration simplifiée du concept d’attention pour un patch dans une image
Aujourd’hui, les modèles les plus performants sont hybrides [4], et composés de deux structures :
- Des modules Transformers pour établir des dépendances globales ;
- Des couches de convolutions pour extraire des caractéristiques locales.
Ainsi, ces modèles profitent des avantages des deux approches.
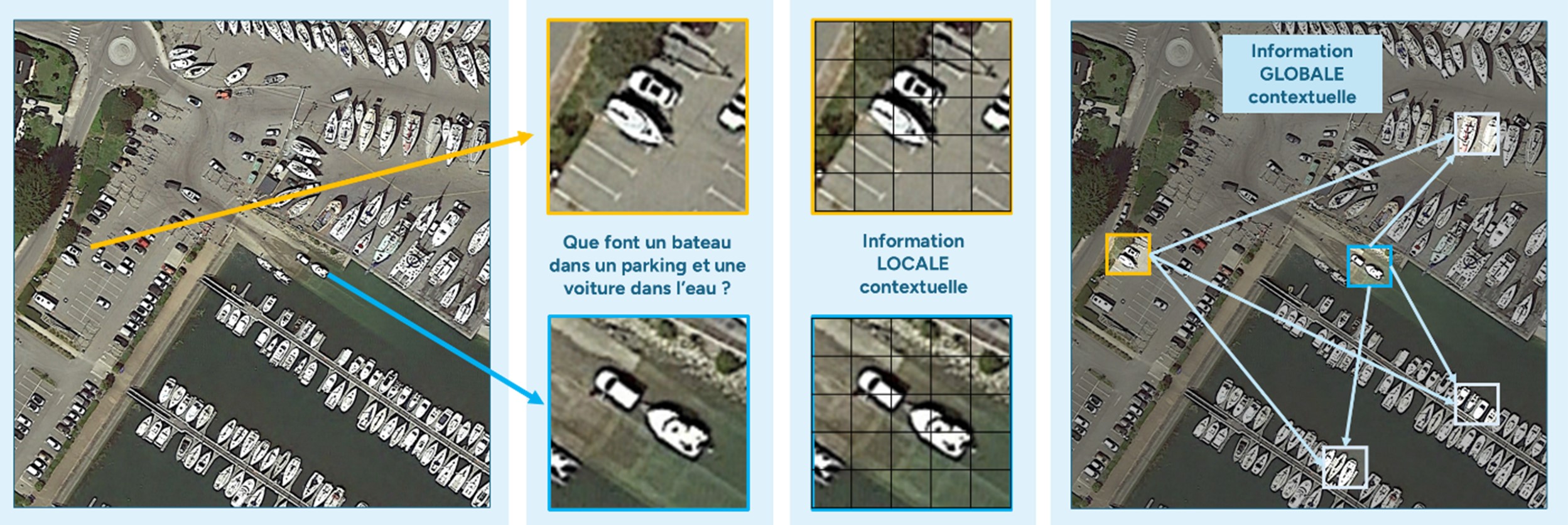
Illustration de l’apport des modèles hybrides dans la segmentation d’objet dans une image aérienne. L’environnement local peut perturber la détection d’un bateau dans un parking. L’information globale apporte un contexte qui permet peut-être de confirmer la détection d’un bateau sur du béton car situé près d’un port.
Défis, enjeux et problématique
Aujourd’hui, les Vision Transformers surpassent les modèles CNN dans de nombreuses tâches. En revanche, leur implémentation pose deux problèmes majeurs :
- Ces modèles sont souvent plus volumineux et nécessitent donc une puissance de calcul accrue, entraînant un coût économique et écologique plus élevé ;
- Les ViT sont connus pour leur forte demande en termes de données. L’annotation des données d’entraînement est essentielle pour obtenir de bonnes performances, mais de tels jeux de données sont relativement rares.
Toutefois, il existe un espoir de surmonter certains de ces obstacles grâce à l’apprentissage auto-supervisé. À suivre…
Bibliographie
[1] Y. LeCun et al. “Backpropagation Applied to Handwritten Zip Code Recognition”. 1989
[2] Alexey Dosovitskiy et al. An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale. 2021
[3] Ashish Vaswani et al. “Attention Is All You Need”. 2017
[4] Haiping Wu et al. CvT: Introducing Convolutions to Vision Transformers. 2021


