
L’apprentissage profond (Deep Learning) nécessite des données annotées pour les différentes problématiques que l’IA peut résoudre sur les images aériennes. Afin d’éviter l’annotation manuelle, de nouvelles méthodes d’apprentissage sans données annotées ont émergé ces dernières années. L’apprentissage auto-supervisé, en particulier, permet de valoriser une quantité abondante de données satellite et aériennes déjà acquises pour pré-entraîner des modèles Deep Learning sans annotation.
L’entraînement
Un modèle de Deep Learning fonctionne de manière similaire au cerveau humain, en utilisant divers signaux d’entrée (comme la vue, le toucher, l’ouïe, etc.) pour établir des connexions, apprendre de ses erreurs et agir en conséquence.
L’objectif de développer un modèle de Deep Learning est d’automatiser une tâche spécifique, actuellement effectuée par des humains, avec des performances égales ou supérieures. Par exemple, dans la segmentation de bâtiments sur des images aériennes, un modèle constitué d’un réseau de neurones artificiels apprend à reconnaître les bâtiments grâce à l’expérience.
Pendant l’entraînement, il analyse des milliers d’images, tente de prédire la localisation des bâtiments et corrige à l’aide d’annotations humaines. Une fois l’entraînement terminé, le modèle peut segmenter les bâtiments sur des images inédites et non annotées.
Illustration d’une phase d’entraînement – cas de la segmentation de bâtiments
Au début de l’entraînement, le modèle est dépourvu de connaissances et commet de nombreuses erreurs. Il nécessite du temps pour apprendre et devenir efficace. L’apprentissage supervisé est onéreux en raison de la nécessité de nombreuses annotations. Pour réduire ces coûts non négligeables, l’apprentissage auto-supervisé peut optimiser ce processus.
Le pré-entraînement auto-supervisé
Pour illustrer le concept de l’auto-supervision, nous allons transposer le processus d’apprentissage chez l’être humain. De nombreuses recherches ont démontré que les nouveau-nés, bien qu’incapables de parler ou de comprendre le langage, acquièrent dès les premiers mois de leur vie des connaissances générales sur leur environnement.
Ils peuvent distinguer des formes [1], des couleurs et même des animaux [2] en se basant sur leurs caractéristiques intrinsèques (comme la couleur et la texture) sans avoir besoin d’une supervision explicite. Ces connaissances forment une base solide que l’enfant utilise ensuite pour diversifier et approfondir son savoir, comme expliqué dans l’article “Self-supervised learning through the eyes of a child” [3].
De manière similaire, l’apprentissage de notre modèle peut être amélioré en le pré-entraînant avec des données non annotées. L’apprentissage auto-supervisé permet au système de se superviser lui-même en utilisant les informations contenues dans les données, sans nécessiter d’annotations humaines.
Il existe plusieurs familles de méthodes auto-supervisées. Elles offrent chacune un moyen différent d’apprendre au modèle à reconnaître des caractéristiques clés dans les images :
- Méthodes contrastives : le modèle apprend à associer des images similaires et à différencier les images différentes ;
- Méthodes prédictives : les images sont modifiées automatiquement (par exemple, en les faisant tourner ou en les découpant comme des puzzles), et le modèle doit prédire ces modifications ;
- Méthodes génératives : une partie des images est masquée automatiquement, et le modèle doit tenter de reconstruire la partie manquante.
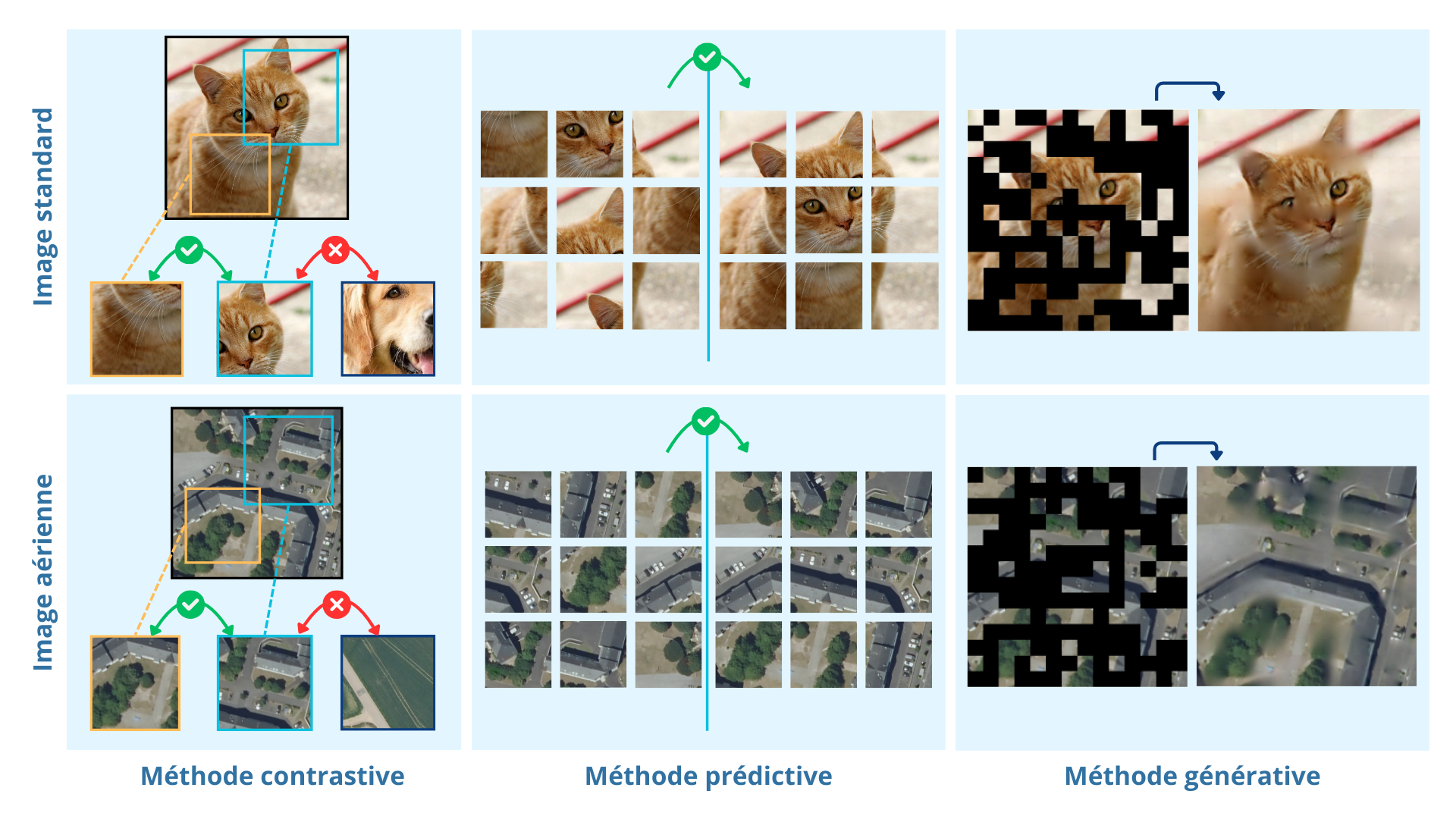
Différentes méthodes d’apprentissage auto-supervisé.
Application : le territoire Français
Au sein du service Innovation, un type de pré-entraînement auto-supervisé a été expérimenté sur des données à grande échelle, en utilisant la base de données BD ORTHO fournie par l’IGN. Elle couvre l’ensemble du territoire français avec une résolution de 20 cm/pixel, une immense source de données aériennes de haute qualité.
À partir de celle-ci, nous avons constitué une base de données qui couvre les différentes régions et types d’environnements en France, avant la mise en place d’une méthode générative appelée « Masked Autoencoder » [4]. Cette méthode utilise les données d’images aériennes et permet au modèle d’apprendre à extraire les informations utiles (formes, couleurs, environnement).
Illustration d’un pré-entraînement auto-supervisé génératif sur la BD ORTHO 20cm
La méthode générative « Masked Autoencoder » offre l’avantage de pouvoir évaluer visuellement la qualité du modèle pré-entraîné. En reconstruisant des images aériennes, cette technique permet au modèle d’apprendre à identifier des formes et signatures distinctives pour restaurer efficacement les zones masquées, comme le montre l’illustration ci-dessous.

Reconstruction d’images aériennes (environnement urbain et rural) en utilisant un Masked Autoencoder pré-entraîné sur la BD ORTHO 20cm.
Défis, enjeux et problématique
Aujourd’hui, l’apprentissage auto-supervisé occupe une place centrale dans le domaine de l’intelligence artificielle. Cette méthode de pré-entraînement se distingue par son approche écologique, car elle augmente la vitesse d’apprentissage des modèles pour des tâches spécifiques, réduit ainsi l’utilisation de machines énergivores et permet surtout une réduction des coûts d’annotation d’image.
Sans supervision humaine pendant le pré-entraînement, les modèles peuvent développer des connaissances non biaisées et générales. L’apprentissage auto-supervisé offre donc plusieurs avantages :
- Il permet de se spécialiser sur une grande variété de tâches ;
- Il réduit les biais souvent introduits par l’annotation humaine ;
- Il économise les ressources matérielles.
De nombreux chercheurs travaillent actuellement sur l’amélioration de ces méthodes, afin que l’apprentissage auto-supervisé remplace progressivement les techniques de pré-entraînement traditionnelles.
Aujourd’hui, certaines techniques font une préanalyse de l’image à reconstruire pour que le modèle ne se concentre que sur les parties les plus intéressantes de l’image [5][6].
Références
[1] P. C. Bomba and E. R. Siqueland, “The nature and structure of infant form categories,” J Exp Child Psychol, vol. 35, no. 2, pp. 294–328, Apr. 1983, doi: 10.1016/0022-0965(83)90085-1.
[2] P. C. Quinn, P. D. Eimas, and S. L. Rosenkrantz, “Evidence for Representations of Perceptually Similar Natural Categories by 3-Month-Old and 4-Month-Old Infants,” Perception, vol. 22, no. 4, pp. 463–475, Apr. 1993, doi: 10.1068/p220463.
[3] A. E. Orhan, V. V. Gupta, and B. M. Lake, “Self-supervised learning through the eyes of a child,” Jul. 2020.
[4] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” Nov. 2021.
[5] F. Wang et al., “Scaling Efficient Masked Autoencoder Learning on Large Remote Sensing Dataset,” Jun. 2024.
[6] L. Fu et al., “Rethinking Patch Dependence for Masked Autoencoders,” Jan. 2024.


